Interfaces Overview
RtBrick Full Stack (RBFS) supports various types of interfaces, including physical and logical interfaces. On hardware platforms, RBFS physical interfaces represent the ports of a switch. This guide describes how to configure and verify RBFS interfaces. Features like routing protocols or access services will typically run on top of the interfaces.
Interface Types
- Physical Interfaces
-
In RBFS, physical interfaces (IFP) typically represent the physical ports of a hardware switch. For example, ifp-0/0/1 represents switch port 1. On the physical interface level, you can configure various parameters associated with Layer 1 of the ISO/OSI reference model.
- Logical Interfaces
-
For each physical interface, you can create one or multiple interface units also referred to as logical interfaces (IFL) in RBFS. A logical interface is associated with the Layer 2 operation. In addition, you can configure Layer 3 parameters like IP addresses on interface units, and assign interface units to routing instances.
- Loopback Interfaces
-
A loopback interface is typically used to represent and identify a device itself. Loopback interfaces are preferred because they do not depend on the status of a physical port, and will always be up. Please note, although loopback interfaces are virtual interfaces, there are also represented as physical interfaces and interface units in RBFS, reflecting Layer 1 and Layer 2/3 operation. Do not configure the broadcast IP address on the loopback interface.
- Host Interfaces
-
Linux virtual ethernet (veth) interfaces connect an LXC container with the Linux host OS. In RBFS, a veth interface to the Linux bridge lxcbr0 is created by default. In virtual topologies, you can create additional veth interfaces and Linux bridges. RBFS host interfaces represent veth interfaces in RBFS.
For example, if the container interface eth1 connects to the host interface vethXYZ123, ifp-0/0/1 can be bound to eth1 to represent it in RBFS. Host interfaces can be used like any other physical interface. - Memory Interfaces
-
Memory interfaces (memif) are virtual interfaces used for creating virtual topologies. They connect multiple containers running RBFS to each other. When configuring memif interfaces:
-
Endpoints match on the memif ID, i.e. the memif ID needs to be the same on both ends.
-
memif IDs need to be unique on the host.
-
The memif interface name is locally significant only.
-
One endpoint needs to be configured as a master, while the other one is configured as a slave.
-
Interface Numbering
RBFS interface numbers match the port numbers on the switch faceplate. An interface is named in the ifp-<chassis-ID>/<front-panel-block-number>/<port> format. For example, ifp-0/0/1.
-
Chassis ID—always 0 for the currently supported platforms
-
Front Panel Block—represents group of ports on the faceplate
-
Port—matches the port number on switch faceplate
Virtual interfaces follow the same structure, for example, lo-0/0/1 or memif-0/0/1.
Logical interfaces are numbered: ifl-<Node ID>/<Chip ID>/<Port ID>/<Unit ID>, for example ifl-0/0/1/1.
Logical Interface Unit Limit
The supported logical interface (IFL) unit number is 16,000. It provides flexibility in naming logical interfaces across a variety of service configurations and is useful for deployments that require large numbers of logical interfaces, such as double-tagged VLAN environments that combine Layer 2 and Layer 3 sub-interfaces.
Reverse Path Forwarding on Logical Layer-3 Interfaces
RBFS supports enabling Reverse Path Forwarding (RPF) in both strict and loose modes on logical Layer-3 IFLs. This feature ensures that packets received on IFLs can be validated against their expected reverse path. It improves security for deployments that rely on Layer 3 IFLs.
This feature is supported on all Q2C and Q2A-based RBFS platforms.
Community Support for Interfaces
You can tag an interface address with a community or extended community. RBFS will create a direct route for each interface address. If a community or extended community is configured for an interface address, RBFS will add it to the direct route. Communities can be used in policies. For example, when redistributing direct routes, you can match these communities and define desired policy rules.
Unnumbered Interfaces
An unnumbered interface is a point-to-point interface that is not explicitly configured with a dedicated IP address; instead, it borrows an IP address from a loopback interface.
For details about configuring an unnumbered interface, see section Logical Interface Configuration.
Unnumbered Interface to Numbered Interface (and Vice versa) Conversion
RBFS supports the conversion of unnumbered to numbered interface and vice versa in a single commit. The existing address should be deleted before converting the interface to an unnumbered interface. These two operations are supported in one commit.
Converting a numbered interface to an unnumbered interface
supervisor@rtbrick>: cfg> delete interface ifl-0/0/0 unit 11 address ipv4 192.0.2.1/24 supervisor@rtbrick>: cfg> set interface ifl-0/0/0 unit 10 unnumbered interface lo-0/0/0/0 supervisor@rtbrick>: cfg> commit
Converting an unnumbered interface to a numbered interface
supervisor@rtbrick>: cfg> del interface ifl-0/0/3 unit 10 unnumbered interface lo-0/0/0/0 supervisor@rtbrick>: cfg> set interface ifl-0/0/3 unit 10 address ipv4 192.0.2.1/24 supervisor@rtbrick>: cfg> commit
Interface States
RBFS supports various interfaces such as physical interface, logical interface, and LAG interface and it uses various indicators to show the various states of interfaces. All interfaces have different states such as the following:
-
Admin state: Indicates whether the interface is enabled (Up) or disabled (Down).
-
Link state: Indicates whether the interface is linked (Up) or not linked (Down).
-
Oper state: Indicates whether the interface is functional (operational) or not functional.
-
IPv4 state: Indicates that the interface is configured with the IPv4 address.
-
IPv6 state: Indicates that the interface is configured with the IPv6 address.
-
MPLS state: Indicates that the interface is an MPLS-enabled interface.
Physical Interface States:
The physical interface states include:
-
admin
-
oper (operational)
-
link
Logical Interface States:
The logical interface states include:
-
admin
-
oper (operational)
-
link
-
IPv4
-
IPv6
-
MPLS
LAG Interface States
The LAG interface states include:
-
admin
-
oper(operational)
The interface state can either be Up or Down. Up shows that it is ready to pass
packets, and Down shows that it is not ready to transmit packets. The operational state shows that the interface is operational and is ready to transmit packets. The Oper state is Up only if both the Admin state and Link state are Up.
Auto-negotiation
Auto-negotiation allows directly connected devices to automatically exchange speed and duplex mode information for the links. If auto-negotiation is enabled, ports can auto-negotiate the speed and duplex capabilities with other ports. The auto-negotiation can determine the best speed and duplex at which the ports can operate optimally.
| Port speed configuration and auto-negotiation are mutually exclusive. |
RBFS supports auto-negotiation between ports in the following ways:
-
1G ports can negotiate with 10G ports.
-
40G ports can negotiate with 100G ports.
Auto-negotiation is not supported for the following combinations:
-
40G ports cannot negotiate with 1G ports, 10G ports, and 25G ports.
-
100G ports cannot negotiate with 1G ports, 10G ports and 25G ports.
-
1G port cannot negotiate with 25G port.
Interface Counters
Interface counters are statistics that network devices maintain for the traffic passing through the interfaces for all physical, logical, and LAG interfaces on a device. These counters provide information about the utilization and performance of the interface. Users can identify and troubleshoot issues such as congestion, errors, and performance bottlenecks by monitoring these counters.
RBFS Logical Interface counters and descriptions
| Counters | Descriptions |
|---|---|
Rx packets |
The number of IP packets received by the logical interface. |
Rx bytes |
The number of bytes received by the logical interface. |
Tx packets |
The number of packets transmitted by the logical interface. |
Tx bytes |
The number of bytes transmitted by a logical interface. |
IPv4 packets |
The number of IPv4 packets processed by a logical interface. |
IPv6 packets |
The number of IPv6 packets processed by a logical interface. |
MPLS packets |
The number of MPLS packets processed by a logical interface. |
Punt packets |
The number of packets that are punted or forwarded to the CPU for further processing by a logical interface. |
Drops packets |
The number of packets that were dropped by a logical interface. |
Rx Miss packets |
The number of packets that were dropped by a logical interface. |
Rx Error packets |
The number of packets that were received with errors by the logical interface. |
Rx No Buff packets |
The number of packets that could not be received due to a lack of buffer space. When a logical interface receives a packet but does not have enough buffer space to store it, the packet is dropped. |
Tx Error packets |
The number of packets that could not be transmitted due to errors encountered during the transmission process. |
Packet Statistics |
|
Ingress forwarded packets |
The number of packets that are received by the device on one interface and then forwarded out on another interface. |
Ingress forwarded bytes |
The number of bytes that are received by a device on one interface and then forwarded out on another interface. |
Ingress drop Packets |
The number of packets that are dropped (discarded) by a network device upon arrival on one of its interfaces by a device. |
Ingress drop bytes |
Total number of bytes that have been dropped by an interface on incoming traffic. |
Egress forwarded packets |
Total number of packets that have been successfully forwarded by an interface on outgoing traffic. |
Egress forwarded bytes |
The number of bytes that have been forwarded by an interface in the egress direction. |
Egress drop packets |
The number of packets that have been dropped by an interface in the egress (outgoing) direction. |
Egress drop bytes |
The number of bytes that have been dropped by an interface in the egress direction. |
RBFS physical interface counters and descriptions
| Physical Interface Counters | Descriptions |
|---|---|
VPP Statistics |
|
Rx packets |
The number of IP packets received by the physical interface. |
Rx bytes |
The number of bytes received by the physical interface. |
Tx packets |
The number of packets transmitted by the physical interface. |
Tx bytes |
The number of bytes transmitted by the physical interface. |
IPv4 packets |
The number of IPv4 packets processed by the physical interface. |
IPv6 packets |
The number of IPv6 packets processed by the physical interface. |
MPLS packets |
The number of MPLS packets processed by a physical interface. |
Punt packets |
The number of packets that are punted or forwarded to the CPU for further processing by a physical interface. |
Drops packets |
The number of packets that were dropped by a physical interface. |
Rx Miss packets |
The number of packets that were dropped by a physical interface. |
Rx Error packets |
The number of packets that were received with errors by the physical interface. |
Rx No Buff packets |
The number of packets that could not be received due to a lack of buffer space. When a physical interface receives a packet but does not have enough buffer space to store it, the packet is dropped. |
Tx Error packets |
The number of packets that were dropped by a physical interface. |
BCM Statistics |
|
inOctets |
Number of octets received through the interface. |
inUcastPkts |
Number of unicast packets received through the interface. |
inNonUcastPkts |
Number of non-unicast packets received through the interface. |
inErrors |
The number of inbound packets that contained errors preventing them from being processed correctly. |
outOctets |
Number of octets sent through the interface. |
ifHCInOctets |
The number of octets (8-bit bytes) received by a network interface. It is a part of the SNMP MIB (Management Information Base) structure and is used to track high-capacity input octets counter used in the context of SNMP monitoring. |
outUcastPkts |
Number of unicast packets sent through the interface. |
outNonUcastPkts |
Number of non-unicast packets sent through the interface. |
outErrors |
The number of outbound packets that contained errors preventing them from being processed correctly. |
etherStatsDropEvents |
Number of events where packets were not delivered to the protocol stack because of resource limitations or other reasons. These dropped events can occur due to buffer overflows, congestion, or hardware limitations. |
etherStatsMulticastPkts |
The number of packets received by an interface that were addressed to a multicast MAC address. |
etherStatsBroadcastPkts |
The number of broadcast packets received on an Ethernet interface. |
etherStatsUndersizePkts |
The number of received packets that are smaller than the minimum allowed Ethernet frame size. Undersized packets can indicate various issues. |
etherStatsFragments |
The number of received packets that are fragments of IP datagrams. |
etherStatsOversizePkts |
The number of received packets that exceed the maximum Ethernet frame size. |
etherStatsOctets |
The total number of octets (bytes) of data transmitted and received on an Ethernet interface. This counter provides a measure of the total amount of data traffic on the interface. |
etherStatsPkts |
The number of packets transmitted or received by an Ethernet interface. This counter can provide insights into the traffic load and performance of the interface. |
dot1dBasePortMtuExceededDiscards |
The number of frames that were discarded at an interface as they exceeded the Maximum Transmission Unit (MTU) of the port. This typically happens when a frame is larger than the maximum size allowed on the interface and cannot be fragmented, so it is dropped. |
etherStatsTXNoErrors |
The number of Ethernet frames transmitted without any errors through the Ethernet interface. Each time a frame is successfully transmitted without encountering any errors, this counter is incremented. |
etherStatsRXNoErrors |
The number of Ethernet frames received without any errors through the Ethernet interface. Each time a frame is successfully transmitted without encountering any errors, this counter is incremented. |
inMulticastPkts |
The number of packets received by the interface that were addressed to a multicast address. These counters provide insights into the amount of multicast traffic being received by the interface. |
outBroadcastPkts |
The number of packets transmitted by the network interface as broadcast packets. These counters can provide insights into the amount of broadcast traffic generated by the interface. |
outMulticastPkts |
The number of packets transmitted by the interface as multicast packets. These counters can provide insights into the amount of multicast traffic generated by the interface. |
outBroadcastPkts |
The number of packets transmitted by the interface as broadcast packets. These counters can provide insights into the amount of broadcast traffic generated by the interface, which can be useful for network troubleshooting and monitoring network performance. |
bcmReceivedUndersizePkts |
The number of undersized packets received by a Broadcom device. Undersized packets are Ethernet frames that are smaller than the minimum allowed size. This counter provides insights into packet size issues. |
bcmTransmittedUndersizePkts |
The number of undersized packets sent by a Broadcom device. Undersized packets are Ethernet frames that are smaller than the minimum allowed size. This counter provides insights into packet size issues. |
etherTxOversizePkts |
The number of packets that exceed the maximum transmission unit (MTU) size allowed on an Ethernet interface. |
etherStatsJabbers |
The number of jabber frames received by an Ethernet interface. Jabber frames are Ethernet frames that exceed the maximum allowed frame size and contain data that extends beyond the maximum length. |
etherStatsCRCAlignErrors |
The number of frames received by an Ethernet interface that has a CRC (Cyclic Redundancy Check) error. Also, the frames are not an integral number of octets in length; that is, the frame length is not a multiple of 8 bits. CRC errors occur when the CRC checksum calculated by the receiving interface does not match the CRC checksum transmitted by the sending interface, indicating that the frame may have been corrupted during transmission |
dot3StatsFCSErrors |
The number of frames that have a Frame Check Sequence (FCS) error received by an Ethernet interface. The FCS is a field in the Ethernet frame that contains a checksum calculated based on the contents of the frame. |
ifHCOutMulticastPkts |
The number of outbound multicast packets on a network interface. The ifHCOutMulticastPkts object uses a 64-bit counter, allowing it to accommodate high-speed interfaces without wrapping around as quickly. It provides an accurate count of the outbound multicast packets on the interface. |
ifHCOutBroadcastPckts |
The ifHCOutBroadcastPkts counter provides the number of outbound broadcast packets on an interface. It is part of the IF-MIB (Interface MIB) and is an extension of the standard ifOutBroadcastPkts counter, providing a 64-bit counter for high-speed interfaces to avoid wrapping around quickly. |
Permanent ARP Entry on IFLs
The Permanent ARP Entry functionality is supported on IFLs. This functionality enables devices to proactively resolve ARP and ND.
Path MTU Discovery
Path MTU Discovery (PMTUD) is a technique that is used to determine the Maximum Transmission Unit (MTU) size that can be used along the path from a source to a destination without requiring fragmentation. PMTUD helps to avoid fragmentation by dynamically discovering the smallest MTU in the path.
PMTUD is crucial for optimizing network performance by avoiding fragmentation.
By default, path MTU discovery is enabled in RBFS.
When RBFS receives packets that violate the MTU, meaning their size exceeds the allowed MTU size, it will respond with the following ICMP error message:
ICMPv4 Message Types
The type field specifies the message type sent by the host, providing detailed information about the error condition.
The following tables show the ICMPv4 message types.
| Type | Description |
|---|---|
3 |
Destination Unreachable. |
Destination Unreachable uses the following code values to further describe the function of the ICMP message being sent.
| Code | Description |
|---|---|
4 |
Fragmentation Needed and Don’t-Fragment (DF) was Set. |
ICMPv6 Message Types
The type field identifies the type of the message sent by the host. The type field contains more specific information about the error condition.
The table below lists the ICMPv6 message type.
| Type | Description |
|---|---|
2 |
Packet Too Big. |
| Code | Description |
|---|---|
0 |
No code |
You can modify this behavior by enabling fragmentation. For details on how to enable hostpath fragmentation, refer to the section 'Enabling Hostpath Fragmentation' below.
All outgoing packets are validated against the configured MTU on the egress path.
-
If MTU is violated and MTU-profile action is
drop, then packets are dropped in hardware. -
If MTU is violated and MTU-profile action is
redirect-to-cpu, a 20MB policer is used to protect the CPU-port from overwhelming MTU-violated traffic, and packets are sent to the CPU port. -
When fragmentation is enabled, one of the following operations takes place.
-
If the DF (Don’t Fragment) bit is not set in the received packet (applicable only to IPv4), the packets are fragmented and sent to the outgoing port.
-
If the DF bit is set in a packet, it drops the packet and sends an ICMP error message back to the source host.
-
-
If the fragmentation is disabled, packets are dropped and ICMP error messages are sent to the source host.
For information on configuring the MTU profile, see MTU Profile Configuration.
IP Fragmentation
If the size of the original IP packet exceeds the MTU of the outgoing interface, the packet must be fragmented.
| RBFS supports IP fragmentation on its Q2C platforms. |
The MTU profile configuration determines if packets exceeding the MTU are dropped or sent to the CPU for further processing.
The forwarding-options configuration includes a setting to enable hostpath fragmentation for packets redirected to the CPU. If this setting is not configured, the device responds with an ICMP error message to the source host.
| MTU fragmentation is not supported on core interfaces configured as LAG. You must disable the re-injection for MTU fragmentation to function on LAG interfaces nn Q2C platforms. |
Guidelines and Limitations of IP Fragmentation
The following guidelines and limitations apply to IP Fragmentation:
-
If a packet exceeds the negotiated subscriber MTU size, the packet is either dropped or fragmented based on the configured MTU profile (applicable only to on the Q2C platforms). The host-path fragmentation is not supported; only an ICMP error message is sent to the source host. For information on MTU profile configuration, see section "MTU Profile Configuration".
You can control fragmentation behavior using the set forwarding-options fragmentation ipv4 state CPU command. For more information about configuring fragmentation, see Enabling Hostpath Fragmentation.
* Fragmented packets are reinjected into the egress pipeline and forwarded through the regular QoS path.
-
No ICMP error messages are generated for MTU-violated multicast packets.
MTU Profile
The Maximum Transmission Unit (MTU) defines the largest packet size that is allowed to transmit across the network.
In the Q2C Platforms, resource efficiency is achieved by using MTU profiles. Components such as IFPs, IFLs, and L3 interfaces reference these MTU profiles. To optimize MTU resource management, you can configure MTU profiles, which can then be applied to various attachment points. The MTU profiles are attached to the physical (IFP), logical (IFL) and L3 interfaces. RBFS supports the following attachment points for MTU profiles.
Attachment Points: The MTU profiles are attached to the interface entities such as physical (IFP), logical (IFL) and L3 interfaces. RBFS supports the following attachment points for MTU profiles:
-
Port-level
-
L3 interface level (IPv4 and IPv6)
-
PPPoE subscriber level (L2 IFL)
-
IPoE subscriber level
MTU Size: A user-configured MTU size can range from 64 to 9216 in RBFS.
| For MTU profiles of type 'pppoe', users should provide L3 MTU size (IPv4/IPv6 headers). |
MTU Type: An MTU type specifies the attachment point of the MTU profile. The MTU types supported are as follows:
-
physical: When checking the MTU, the total size of the packet, including headers, is considered.
-
ipv4: The MTU check is conducted based on IPv4 headers.
-
ipv6: The MTU check is conducted based on IPv6 headers.
-
ip: MTU profile of type IP and IPoE.
-
pppoe: The MTU profile is applied to the PPPoE subscriber interface, where you must specify the L3 MTU size. Using its best-match algorithm, the subscriber management service associates these profiles with PPPoE subscribers.
|
MTU Action:
The MTU action specifies the response when an MTU check fails. The following actions are supported:
-
drop: This indicates that when the MTU check fails, the action "drop" is performed. -
redirect-to-cpu: This is an action of redirecting packets to the CPU in a traffic behavior. Theredirect-to-cpu actionmust be configured for the fragmentation to work.
MTU Profile Limitations
The MTU profile has the following limitations.
-
The MTU violation trap is signalled at the ETTP stage (Egress) of the pipeline. Therefore, it is expected that the bandwidth consumed by dropped packets due to MTU violations will be accounted for.
-
Each hardware unit supports a limited number of MTUs. Therefore, the following limits apply.
-
MTU Profile Limits by Platform:
-
Q2C Platform:
-
Total MTU profiles supported: 8
-
L3 MTU profiles (IP/IPv4/IPv6): Up to 3
-
PPPoE MTU profiles: Up to 6 (including the default PPPoE profile)
-
Physical MTU profiles: Up to 7
-
-
QAX Platform:
-
Physical MTU profiles: 1 only
-
-
Interface Holddown
Overview
Interface Holddown or Interface Dampening is a delay mechanism to prevent network instability from flapping interfaces. Interface flapping occurs when an interface goes up and down repeatedly, leading to excessive route recalculations and needless notifications to other software components.
The Interface Holddown feature is used to prevent network instability by temporarily damping the interface state if it is fluctuating. This mechanism suppresses frequently fluctuating routes and ensures that only stable routes are advertised. It improves overall network performance by effectively utilizing resources such as memory and processing power.
| The Interface Holddown feature remains supported when interfaces are grouped in a LAG. |
Option to Disable
By default, the Interface Holddown feature is enabled on RBFS. You can configure the ‘hold-down down delay’ and ‘hold-down up delay’ parameter values using the configuration commands. You can also disable the feature using the command.
Benefits of Interface Holddown
Frequent updates due to route flaps can consume significant processing capacity. This can increase the CPU load on routers, and the constant route advertisements and withdrawals can consume bandwidth. The Interface Holddown mechanism minimizes unnecessary route recalculations and notifications, and the number of updates that need to be processed by suppressing frequently flapping routes. Suppressing unstable routes can improve overall network performance by ensuring that only stable routes are advertised and used for forwarding traffic.
How RBFS Interface Holddown Works
When an interface flaps, such as an interface goes up and down frequently, RBFS employs a holddown period during which the interface’s status is retained in its previous state.
The holddown time for an interface increases exponentially within a defined range. The values can be configured explicitly for each interface. When an interface flap occurs, the interface management daemon receives this event from the hardware through the FIBD.
The following diagram shows the interface holddown feature.
The holddown intervals are set at 0ms, 100ms, 200ms, 500ms, 1s, 2s, 5s, and 10s. When the holddown timer expires, the interface state is propagated to higher layers. If the interface remains stable throughout the holddown interval, the actual state is propagated. However, if the interface experiences instability during this interval, it remains in the DOWN state.
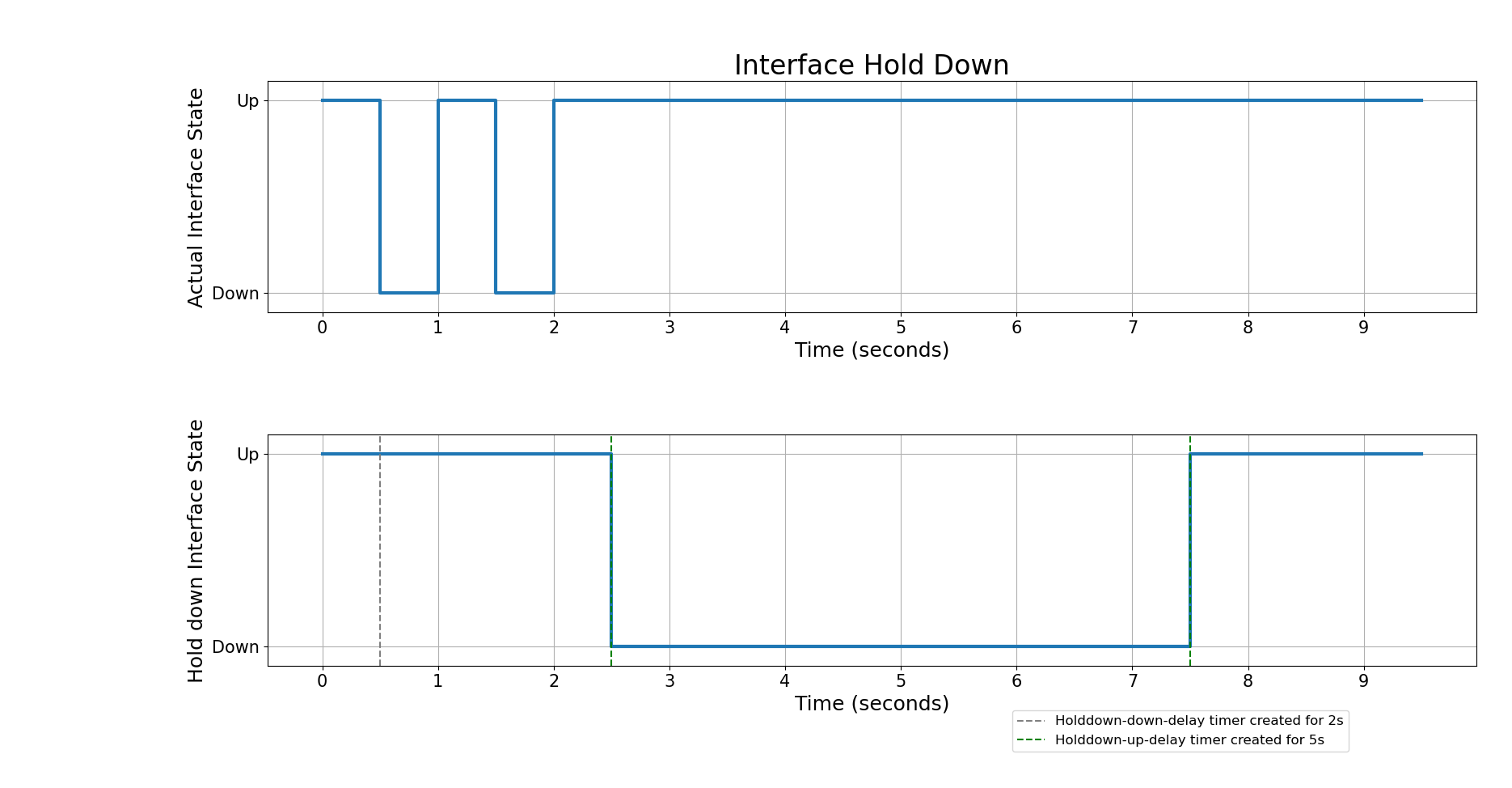
RBFS implements "Holddown Down Delay" and "Holddown Up Delay", two parameters that control how the interface flap is managed.
Holddown Down Delay
The ‘Hold-down Down Delay’ parameter, once configured, ensures that the interface state change from UP to DOWN is delayed by the specified ‘holddown down delay’ period. After this delay, the default holddown mechanism takes over. Specifically:
-
The ‘holddown’ interval starts with its initial value, that is 'holddown down delay' period, and increments exponentially when each timer expires.
-
DOWN to UP state changes are delayed based on exponentially increasing intervals.
The following diagram shows 'holddown down delay' scenario.
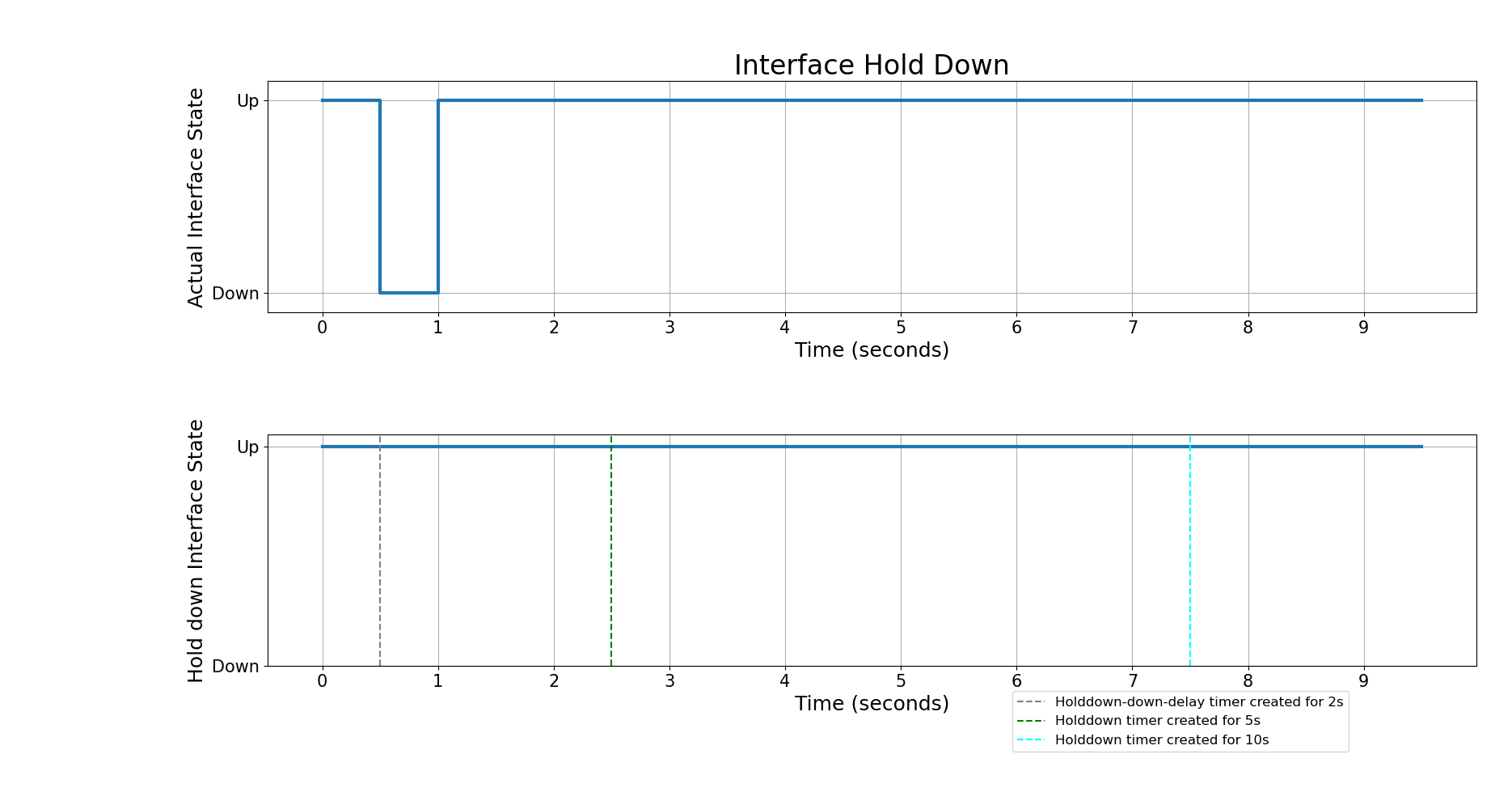
For example, if the ‘holddown down delay’ is set to 5 seconds and the interface state changes from UP to DOWN, the interface remains up for 5 seconds. After this 5-second delay, the system checks the stability of the interface:
-
If the interface has no flap during this period, it remains up.
-
If the interface has flapped during this period, it changes to the DOWN state after the delay.
In summary, Holddown Down Delay ensures an interface remains up for a specified time before propagating any state change to higher-level software components.
Holddown Up Delay
'Holddown Up Delay' is the period that an interface stays down after a failure before it is considered to be in a stable state. When the state changes from DOWN to UP, a holddown timer is initiated with a specified delay period. If there are flaps during the previous interval time, then a new timer with the same 'holddown up' delay is set.
This results in a delay in the state transitioning to UP based on the ‘holddown up delay’. However, if state changes happen within the 'holddown up delay' interval, any change from UP to DOWN is immediately transmitted. It uses a static timer instead of an exponential backoff for the holddown interval.
NOTE:
The following diagram shows 'holddown up' scenario.
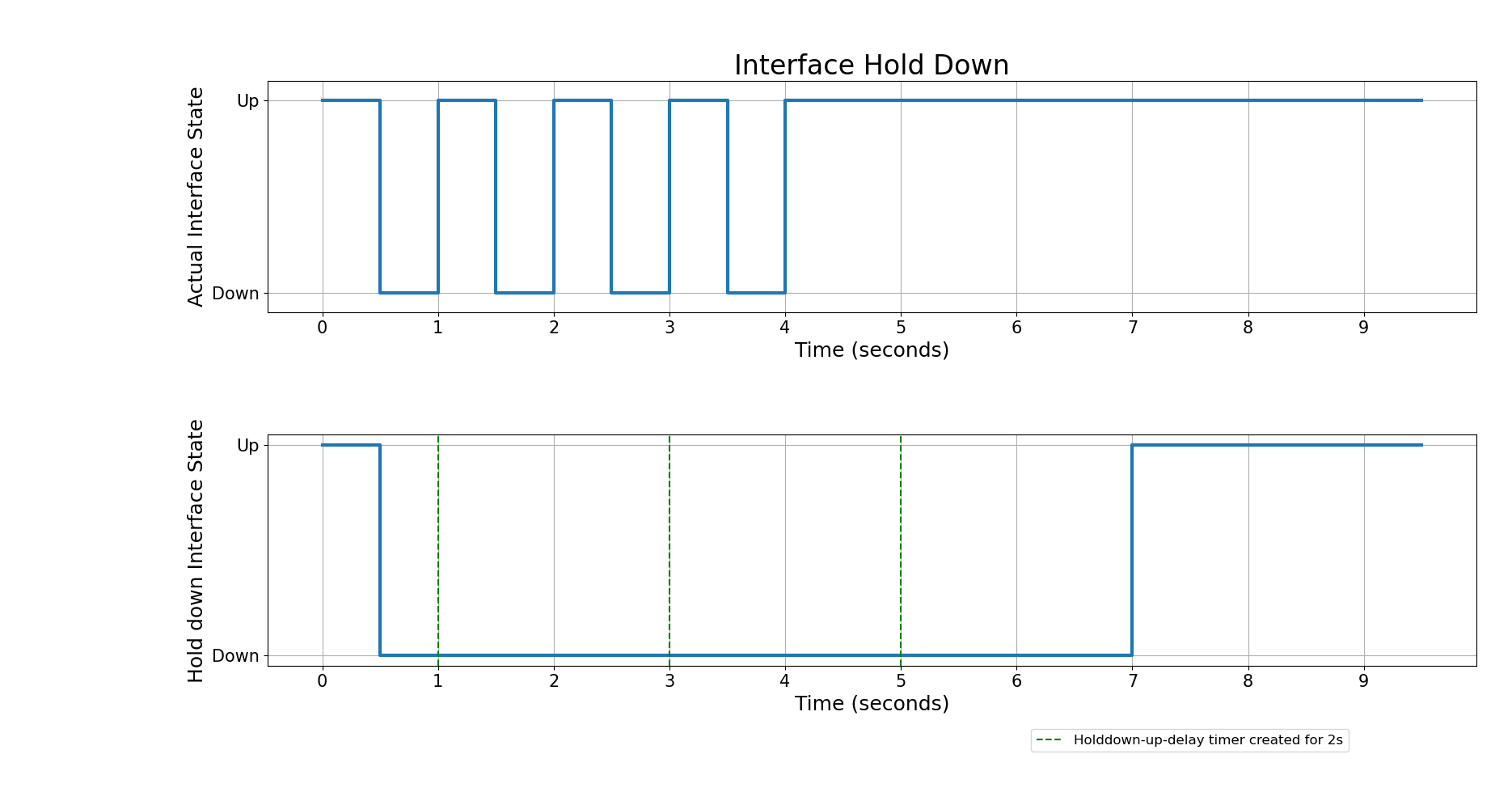
Example Scenario
Imagine where a router’s interface occasionally loses and regains connectivity due to a loose cable. Each time this happens, it creates an event that propagates through many of the software components in the network.
Without the Interface Holddown feature, every time disruption immediately triggers network protocols and higher-level software components to respond, potentially causing routing updates, recalculations, and additional processing overhead. This constant back and forth leads to network instability and adds additional strain on network devices.
With the interface Holddown enabled, the RBFS still receives these flap events but employs a hold-down mechanism to delay taking action on these changes. For example, with the holddown intervals: 0ms, 100ms, 200ms, 500ms, 1s, 2s, 5s, and 10s, the system performs the following:
-
Retain the old interface status when an interface flap is detected.
-
Wait for the initial hold-down time, which is 100ms.
-
If another transition occurs within this period, the hold-down time increases to the next interval that is, 200ms. This process repeats, increasing the hold-down time after each transition up to the configured maximum value, which is 10s.
In this way, by delaying the processing of interface flaps, interface dampening reduces the impact of flapping on the network. The system only updates the interface status after a stable period without transitions, thus preventing frequent, unnecessary updates.
IPv6 Link-Local Address
In IPv6 networking, link-local addresses are essential for local communication between nodes on the same link. It facilitates communication between nodes on the same link, however cannot be used to send packets beyond that link.
In RBFS, a link-local IPv6 address can be either automatically generated or manually assigned.
When a configured link-local address is deleted, a unique link-local address is automatically generated for the logical interface. This automatically assigned address is typically derived from the interface’s MAC address and other parameters.
You can also modify an existing automatically generated link-local address by manually configuring a link-local IPv6 address on a logical interface. It will replace the auto-generated link-local address with the one you have configured.
Guidelines & Limitations
QAX-based Platforms
An additional restriction applies to ports on QAX-based platforms: because of hardware design, physical ports are grouped into quads (groups of 4, also known as port groups). Each quad must have the same physical parameters: speed, link-training, duplex.
The following tables are provided for easy identification of ports that need to have the same physical settings:
Edgecore 7316-26XB Port Groups:
| Port | Speed | Duplex | Port Group |
|---|---|---|---|
ifp-0/0/0 |
100G |
Full |
0 |
ifp-0/0/1 |
100G |
Full |
1 |
ifp-0/1/0 |
10G |
Full |
2 |
ifp-0/1/1 |
10G |
Full |
|
ifp-0/1/2 |
10G |
Full |
|
ifp-0/1/3 |
10G |
Full |
|
ifp-0/1/4 |
10G |
Full |
3 |
ifp-0/1/5 |
10G |
Full |
|
ifp-0/1/6 |
10G |
Full |
|
ifp-0/1/7 |
10G |
Full |
|
ifp-0/1/8 |
10G |
Full |
4 |
ifp-0/1/9 |
10G |
Full |
|
ifp-0/1/10 |
10G |
Full |
|
ifp-0/1/11 |
10G |
Full |
|
ifp-0/1/12 |
10G |
Full |
5 |
ifp-0/1/13 |
10G |
Full |
|
ifp-0/1/14 |
10G |
Full |
|
ifp-0/1/15 |
10G |
Full |
|
ifp-0/1/16 |
25G |
Full |
6 |
ifp-0/1/17 |
25G |
Full |
|
ifp-0/1/18 |
25G |
Full |
|
ifp-0/1/19 |
25G |
Full |
|
ifp-0/1/20 |
25G |
Full |
7 |
ifp-0/1/21 |
25G |
Full |
|
ifp-0/1/22 |
25G |
Full |
|
ifp-0/1/23 |
25G |
Full |
|
UfiSpace S9500-22XST Port Groups:
| Port | Speed | Duplex | Port Group |
|---|---|---|---|
ifp-0/0/0 |
10G |
Full |
8 |
ifp-0/0/1 |
10G |
Full |
|
ifp-0/0/2 |
10G |
Full |
|
ifp-0/0/3 |
10G |
Full |
|
ifp-0/0/4 |
10G |
Full |
4 |
ifp-0/0/5 |
10G |
Full |
|
ifp-0/0/6 |
10G |
Full |
|
ifp-0/0/7 |
10G |
Full |
|
ifp-0/0/8 |
10G |
Full |
11 |
ifp-0/0/9 |
10G |
Full |
|
ifp-0/0/10 |
10G |
Full |
|
ifp-0/0/11 |
10G |
Full |
|
ifp-0/0/12 |
25G |
Full |
3 |
ifp-0/0/13 |
25G |
Full |
|
ifp-0/0/14 |
25G |
Full |
|
ifp-0/0/15 |
25G |
Full |
|
ifp-0/0/16 |
25G |
Full |
2 |
ifp-0/0/17 |
25G |
Full |
|
ifp-0/0/18 |
25G |
Full |
|
ifp-0/0/19 |
25G |
Full |
|
ifp-0/0/20 |
100G |
Full |
0 |
ifp-0/0/21 |
100G |
Full |
1 |
A PHY Quad can be associated with network interface (NIF) ports of identical type only. For example, a quad cannot be a mix of XLGE and XE ports. An exception is GE and XE ports which can coexist in the same quad. This means all the ports in a port group should have the same physical interface configuration (that is, speed/duplex/link-training). Ports in a port group are only allowed to support 1G and 10G speeds; any other combination is not allowed. If a port within a port group is misconfigured, then it would require changing the speeds/interface type of all ports within the port group to a different type and then back into the original type.
Support for TTL Inheritance from IP to MPLS
RBFS support for inheriting the IP TTL into the MPLS TTL at the ingress node by enabling TTL propagation. It ensures traceroute visibility across the MPLS network.
| By default, the IP TTL is not inherited at the MPLS ingress node and the MPLS TTL is set to the value '64'. |
Supported Platforms
Not all features are necessarily supported on each hardware platform. Refer to the Platform Guide for the features and the sub-features that are or are not supported by each platform.